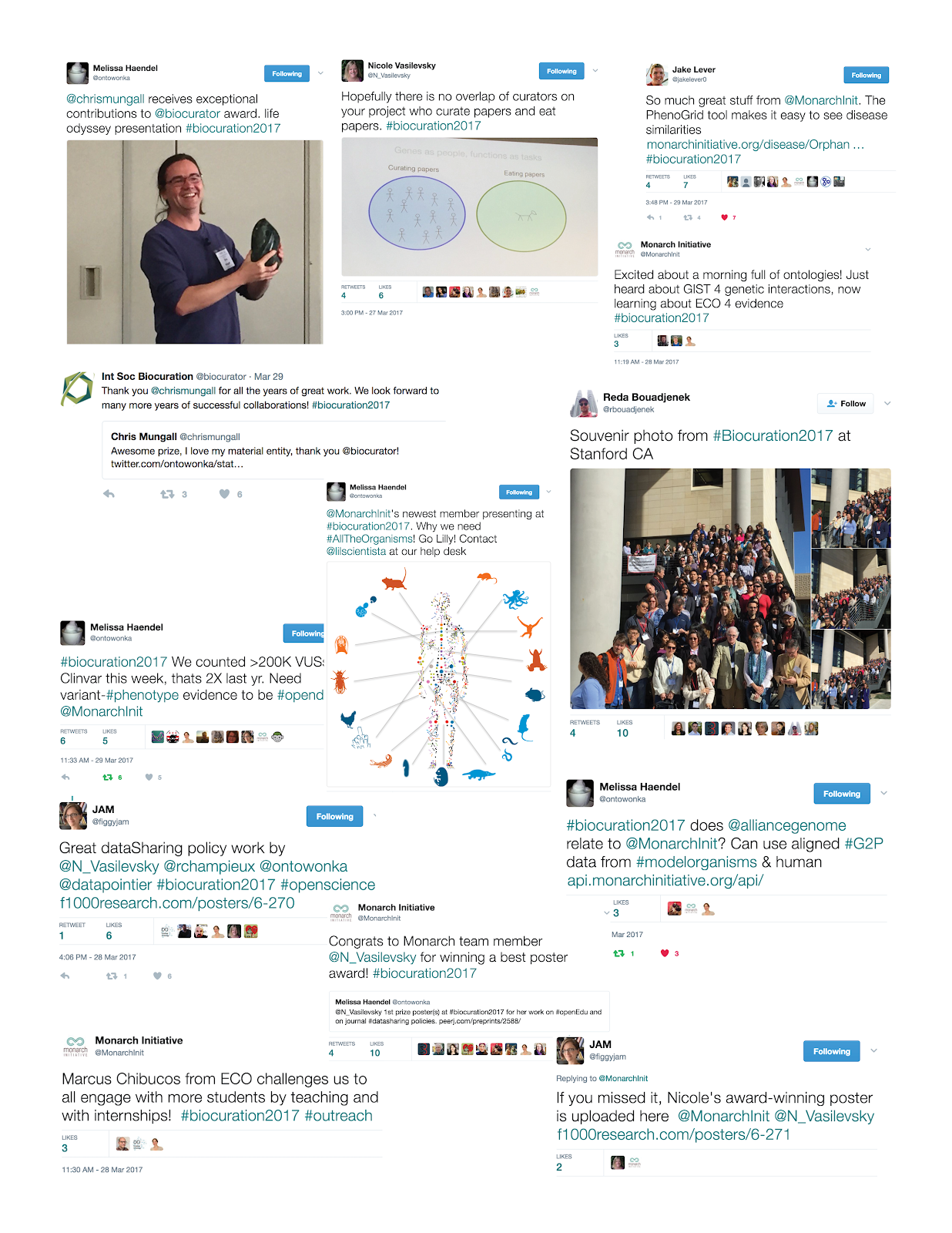
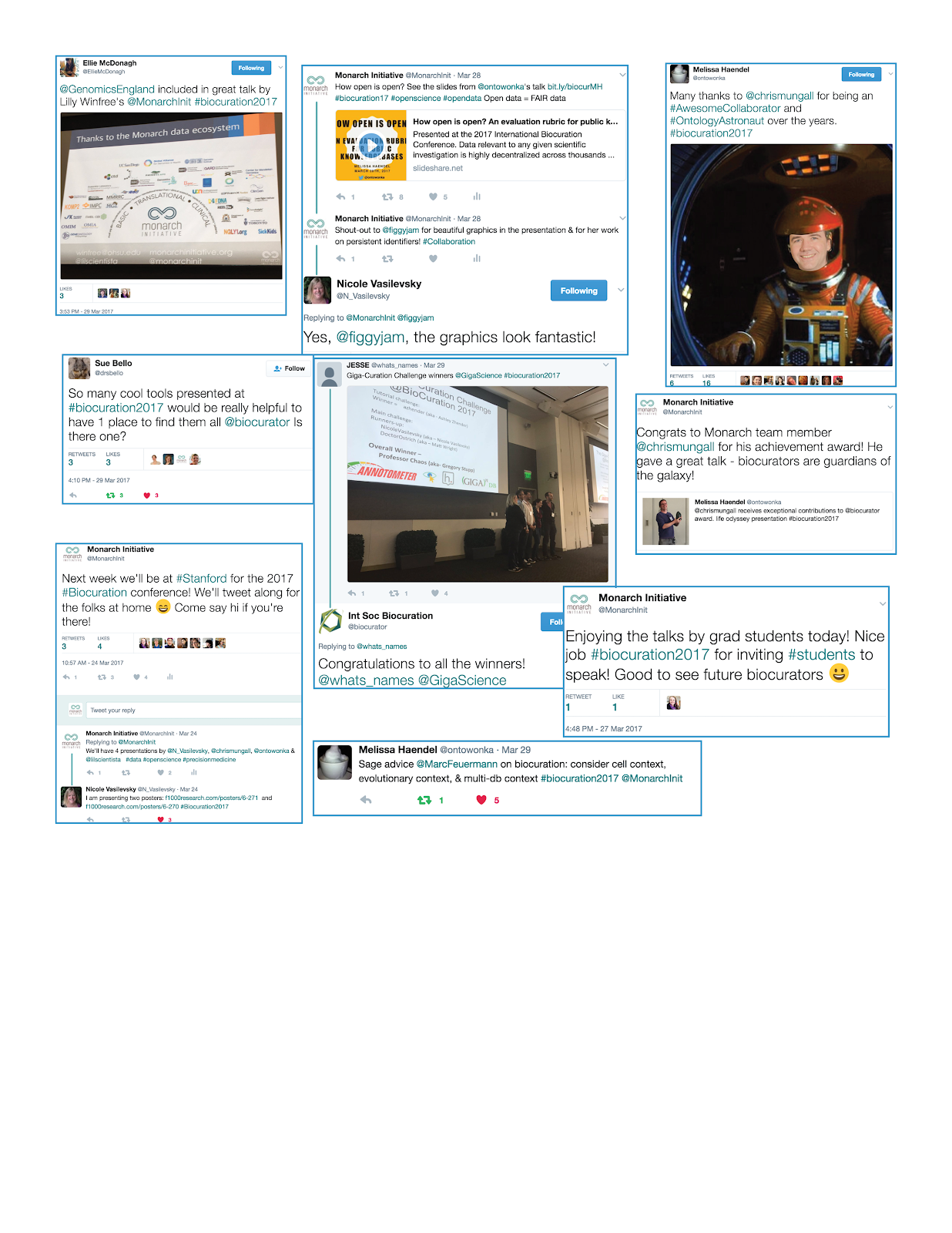
Several members of the Monarch Initiative convened upon sunny Palo Alto, CA for the International Society for Biocuration (ISB) annual meeting. The meeting, held at Stanford University from March 26-29, 2017, brought together experts in the field of biocuration and included presentations, posters, and workshops on the topics of curating biological data, database creation and maintenance, community annotation, and education. Between brief, but glorious, moments of sun soaking (reminder: several of us are from rainy Portland), we enjoyed meeting our fellow biocurators and presenting talks and posters. Here’s a brief overview of the presentations from four Monarch team members, including links to the slides and posters in case you missed them!

Melissa Haendel, Monarch co-PI, presented a talk titled “How Open is Open?” discussing the open science principles of FAIR TLC. Here, FAIR TLC stands for making data: Findable, Accessible, Interoperable, Reusable, Traceable, Licensed, and Connected. Melissa discussed how we can use the FAIR TLC principles to evaluate open biological databases and repositories and go beyond traditional evaluation metrics, such as publication numbers. You can view her talk slides here: bit.ly/biocurMH.

New Monarch team member, Lilly Winfree, presented in the precision medicine session on how Monarch uses various ontologies to semantically integrate genotype and phenotype data from multiple species with a goal of disease diagnosis for patients. Lilly explained how Monarch semantically integrates this data using the ontologies GENO (for genotypes) and SEPIO (Scientific Evidence and Provenance Information Ontology), which have been spearheaded by Monarch ontologist Matt Brush. Lilly also showed a use case of the Exomiser tool, which is currently being utilized by Genomics England to identify pathogenic variants. You can view Lilly’s slides here.

Chris Mungall, Monarch co-PI, was awarded the ISB Exceptional Contributions to Biocuration Award. Congrats, Chris! In his acceptance talk, Chris described his career path, including his brief stint as a chicken farmer! Or maybe not quite a chicken farmer...you’ll have to ask Chris for the details. We also learned that Chris and fellow award-winner Marc Feuermann share a love of science fiction, and have both authored sci-fi stories.

Nicole Vasilevsky, Monarch project manager, presented two posters, which both won a best poster award at the conference! Nicole also won an award for a community annotating contest, hosted by GigaScience, using the iCLiKVAL and Hypothesis.is tools. Great work, Nicole!
Nicole’s poster titled “Training future biocurators through data science trainings and open educational resources” was co-authored by several OHSU faculty: Ted Laderas (DMICE), Jackie Wirz, Bjorn Pederson (DMICE), David Dorr (DMICE), Bill Hersh (DMICE), Shannon McWeeney (DMICE) and Melissa Haendel. The poster, available here, described development of in-person data science trainings offered as short courses to OHSU students, and the development of Open Educational Resources (OERs) that are available online (dmice.ohsu.edu/bd2k). Conference attendees were particularly interested in the BD2K tutorials on topics related to biocuration (such as BDK05 on Data Standards and BDK12 on Data annotation and Curation), as there is a lack of formal training in biocuration. Several biocuration efforts discussed at the conference involved crowd-sourced efforts, so these tutorials will be useful for training contributors to these community databases. I encourage you to check out these interesting tutorials!
The second award-winning poster titled “A need for better data sharing policies: a review of data sharing policies in biomedical journals” described a project led by Robin Champieux and co-authored by Nicole, Jessica Minnier (from the OHSU-PSU School of Public Health) and Melissa Haendel, and is available here. This poster described an analysis of biomedical journal data sharing policies. It is widely agreed that data sharing is important for ensuring transparency of research results and scientific reproducibility (and data sharing will certainly facilitate biocuration efforts to extract information from the literature into databases). This analysis showed that approximately 40% of journals (in our sample) either required or strongly encouraged data sharing upon publication. The data from this analysis is shared here (which includes a list of journals that require or encourage data sharing) and we hope that researchers will publish in those journals that require data sharing. A preprint is available here, and the manuscript has been accepted for publication in PeerJ and will be available soon.
Photos from the conference can be viewed here.
Biocuration F1000 channel presentations: https://f1000research.com/channels/biocuration
Written by Nicole Vasilevsky and Lilly Winfree