
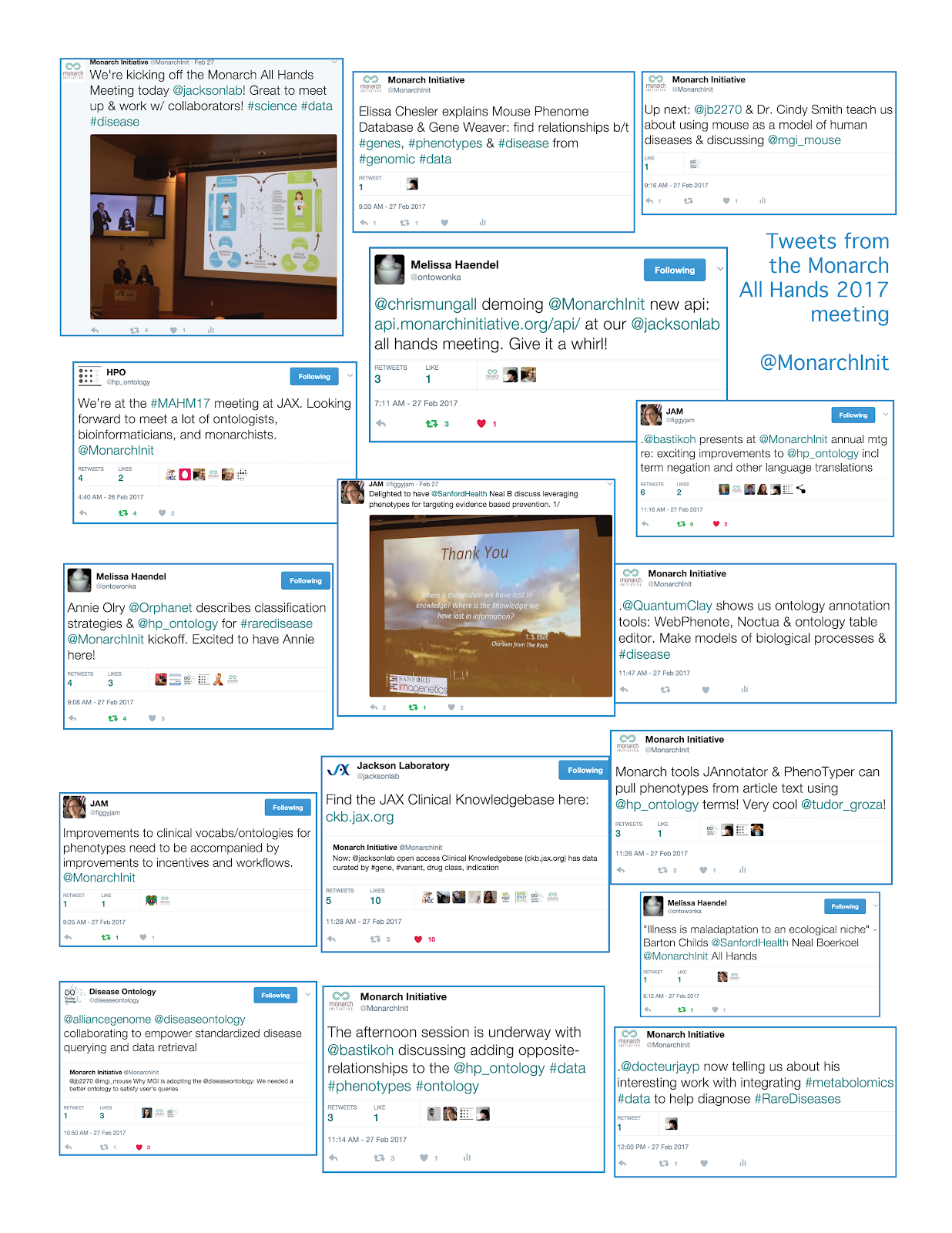
At the end of February, the global members of the Monarch Initiative convened at the Jackson Laboratory in Farmington, Connecticut for our annual All-Hands Meeting. This collaborative meeting allowed us to set goals for 2017, have hands-on working time for various projects, bond over an epic Hibachi meal, and compete in giant Jenga. Since the Monarch team works around the globe, the All-Hands Meeting was a unique chance for everyone to gather in the same room. As a new member to the team, I particularly enjoyed meeting the rest of my coworkers in person - instead of over video chat! The meeting was a big success, yet it ended on a dramatic note when several of our flights were canceled, resulting in three-hour-long taxi rides and an impromptu trip to Waffle House.
In this post I will mention some of the highlights from the meeting as well as the goals we discussed for the upcoming year and how these goals fit into three main themes: ontologies, tools, and collaborations.
A hallmark of the Monarch Initiative is work on the underlying ontologies, which was reflected during the meeting with discussions on several phenotype and disease ontologies. Monarch team members and colleagues presented work on the Human Phenotype Ontology (HPO), the Mammalian Phenotype Ontology, and Upheno, which is the "uber phenotype ontology" that combines all species-specific ontologies. We also heard about advances with the Disease Ontology and the Merged ONtology of Disease Objects (MonDO). Goals for the upcoming year include further developing the HPO and MonDO and increasing the ontology browsing capability on the Monarch webpage. The Monarch Team is also composing two ontology-rich manuscripts that will be published in the near future: one detailing the inclusion of lay person synonyms into the HPO, and the second explaining the development of the Genotype Ontology GENO. You can read more about how we incorporate these ontologies here: https://monarchinitiative.org/page/about.
Nicole Vasilevsky, Monarch Project Manager, describes MonDo as being "created using novel mechanisms to semi-automatically merge multiple disease resources to yield a coherent merged ontology. This ontology should aid users to find relevant information related to diseases of interest." Importantly, Nicole was designated as the MVP of the meeting as she actively contributed to Monarch ontologies during the meeting! Good work, Nicole!
During the meeting, there were several fascinating demos on Monarch tools as well, such as the Exomiser. Clinicians and researchers can use the Exomiser, which is a Java tool, to analyze genomic information for disease-causing variants and also compare phenotypes across species using the PhenoDigm algorithm. We also learned how to use the Monarch tools JAnnotator and PhenoTyper, which automatically select phenotype terms from journal article text, allowing those terms to then be used in phenotypic comparisons. Another interesting tool developed by the Monarch team is PhenoPackets, which I wrote about for Open Data Day. Many of these tools are still being actively designed, and we would love feedback (via email or write a Github issue) if you or your group have used these tools.
During the first day of our meeting, we had the pleasure of hearing from several of Monarch’s guests and collaborators. First, Sanford Imagenetics discussed precision public health and the role that Monarch tools can play in advancing patient health. Next David Adams from the Undiagnosed Disease Program spoke about how Monarch and the NIH can work together to improve diagnosis of rare diseases. Jean-Philippe “JP” Gourdine, research associate in glycobiology and metabolomics at OHSU, gave an interesting talk in which he introduced the use of metabolomics data for gene prioritization in the context of the Undiagnosed Diseases Network. JP and Matt Brush, Monarch Ontologist, also discussed the integration of the molecular glycophenotypes ontology (MGPO) into the HPO. Our next guest came all the way from Paris to represent Orphanet; Annie Olry explained the ongoing analytical work behind Orphanet’s portal on rare diseases. The next three presentations came from members of the Jackson labs, our gracious host for the meeting. Judith Blake and Cindy Smith demonstrated how the Mouse Genome Informatics resource is incorporating the Disease Ontology. The next presenter was Elissa Chesler, who showed us GeneWeaver, which is an interesting tool that can integrate heterogeneous genomic data. To round out the session, Sue Mockus discussed Jackson’s Clinical Knowledgebase tool for exploring genomic profiles. These presentations highlighted the important role that collaboration plays in the Monarch Initiative -- we thank our guests for joining us and helping make this Monarch All Hands meeting a success!
- You can view the Monarch All Hands Meeting presentation slides here.
- HPO crowd sourced contributions and suggestions are welcome, submit via the tracker: https://github.com/obophenotype/human-phenotype-ontology
- Follow us on Twitter @MonarchInit
 |
| Epic Jenga battle |


 |
| Leadership dinner |
 |
| Code time |
 |
| Sporting Monarch T-shirts |
 |
| Before the taxi rides! |
 |
| Hibachi dinner |